

AI-Driven, Speech-Based Job Interview Simulator
I was building an AI-driven, speech-based job interview simulator where a Python backend and a Unity frontend communicate with each other in real time.
The system is unique because it operates in both online and offline modes.
Online Mode
- Uses OpenAI / gpt 4o mini for interview logic
- Produces higher-quality, more structured responses
- Paid service, therefore not always ideal
Offline Mode
- Uses a locally hosted LLM via Ollama
- Fully offline, controlled environment
- Slightly lower response quality, but self-hosted and scalable
Tech Stack
Backend (Python)
- LLM selection: online (gpt 4o mini) / offline (Ollama)
- XTTS - neural text-to-speech (always offline)
- WebSocket-based bidirectional real-time communication (no FastAPI)
- Audio processing and lip-sync data generation
- Multilingual support: Hungarian and English
Frontend (Unity)
- Real-time UI and interaction
- Avatar rendering, animation, and lip-sync
- Handles backend events (question, answer, speech, state updates)
Special Feature
Interviewer's voice: Magyar Péter
Candidate's voice: My own voice via voice cloning
This makes the simulation not only technically advanced, but also psychologically realistic.
Futures - TTS
- XTTS (offline)
- ElevenLabs (online)
What Does the System Actually Do?
This is not a chatbot — it is an interview system.
It conducts technical interviews (e.g., software engineering roles).
Communication is speech-based, not just text-based. The backend does not simply “respond” — it actively leads and structures the interview.
System Design Level
This project touches senior/staff-level system design challenges:
- AI decision-making logic
- Real-time communication architecture
- Offline–online fallback strategies
- Game engine integration
Performance Requirements
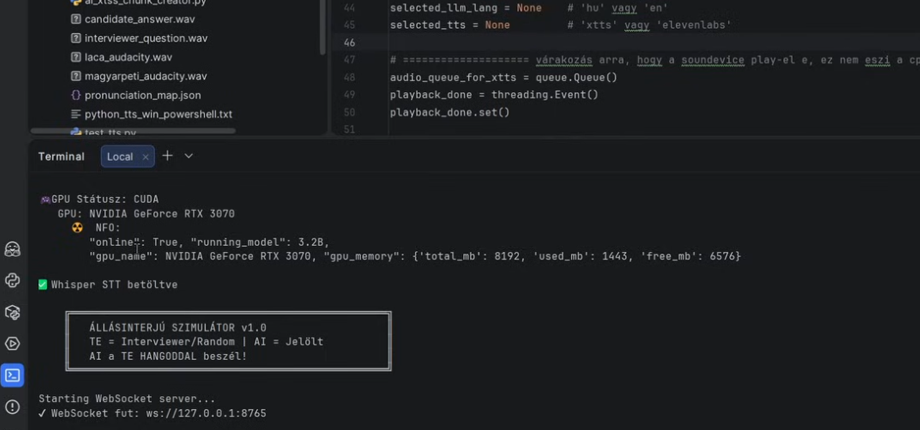
The system is heavily optimized to maintain speed at all times and avoid unnecessary latency.
Minimum requirement: RTX 3070 with available CUDA capacity.
All other GPU-intensive processes should be disabled.
MEDIA

CONTACT